R studio server를 AWS에 설치하고 가장 큰 문제는 데이터 가져오기이다.
구글 드라이브에 데이터를 올리고 불러오거나 github에 올리고 가져오는 방법도 있지만,
우리는 AWS를 쓰고 있으니 S3를 사용해서 하기로 하자.
참고로 이 글은 AWS에서 기본적으로 제공하는 Linux[centOS]를 기반으로 작성되었다.
R studio server를 AWS에 설치하고 가장 큰 문제는 데이터 가져오기이다.
구글 드라이브에 데이터를 올리고 불러오거나 github에 올리고 가져오는 방법도 있지만,
우리는 AWS를 쓰고 있으니 S3를 사용해서 하기로 하자.
참고로 이 글은 AWS에서 기본적으로 제공하는 Linux[centOS]를 기반으로 작성되었다.
dplyr과 arulesViz 설치를 github로 하는 법을 찾다가 devtools라는 패키지가 필요하게 되어 설치하는 법을 찾아 보았다.
결론부터 말하면 dplyr과 arulesViz 설치를 원하면 t2.micro로는 안된다.
용량부족…
이번 설치는 따로 사진 첨부는 없이 커맨드로 진행한다.
일단 command를 킨다.
AWS라면 putty로 연결하면 된다.
sudo yum -y install libcurl libcurl
sudo yum -y install openssl-devel
위의 2 커맨드를 입력하고 나면 Rstudio로 접속하여 다음과 같이 입력한다.
install.packages(“devtool”, type=’source’)
사실 저번 RMySQL & DBI 설치와 매우 흡사하다.
CentOS라는 특수상황에서 이런 경우는 매우 많이 겪을 수 있다.
devtools 라는 패키지를 설치하면 install_github()를 통해 이제 github로 부터 패키지를 다운 받을 수 있게 됨으로 유용하게 사용이 가능하다.
추가로, dplyr나 arulesViz를 설치하려면 AWS는 t2.micro(free tier)보다 용량이 큰 것의 instance를 생성해야한다.
출처 :
https://stackoverflow.com/questions/20923209/problems-installing-the-devtools-package
RMySQL과 DBI는 R과 MySQL을 같이 사용하도록 도와주는 패키지이다.
헌데 이 패키지는 install.packages()로는 설치가 되지 않는다.
그러므로 다음과 같은 작업이 필요하다.
그래서 구글에 ‘rmysql install centOS’라고 검색해보았다.
그랬더니 다음과 같은 동영상을 발견할 수 있었다.
위 동영상과 같이 작업하면 문제 없이 설치 될 것이다. 그래도 문서로 작성해 보면,
일단, putty를 이용하여 AWS EC2 instance에 연결한다.
sudo yum install mysql-devel
sudo yum install r-devel
위 두 명령으로 r-devel과 mysql-devel을 설치한다.
다음 R을 실행시키고
R
install.packages(‘DBI’, repos=”http://cran.stat.nus.edu.sg/ “)
위처럼 입력하면 ‘DBI’ 패키지를 설치하게 된다.
다음으로,
install.packages(‘RMySQL’, repos=”http://cran.stat.nus.edu.sg/ “)
위처럼 입력하여 ‘RMySQL’ 패키지를 설치한다.
이로써, 영상은 ‘Done!’ 이라며 끝나게 된다.
하지만, 우리는 여기서 한가지 더 해야한다.
install.pacakges(‘DBI’, type=’source’)
install.pacakges(‘RMySQL’, type=’source’)
이렇게만 하여야 library() 함수를 이용해서 불러올 수 있게 된다.
우리가 ‘RCurl’ 같은 경우는 install.pacakges(“RCurl”)만 해도 설치가 가능하다.
그런데 왜 ‘RMySQL’, ‘DBI’, ‘dplyr’ 등과 같은 packages는 바로 설치가 안될까?
이유는 cpp로 작성되어 있기 때문이다.
그렇기 때문에 type=’source’로 하여금 install 할 필요가 생긴다.
다음에는 위 패키지들로 R에서 MySQL로 연결하는 것을 알아보도록 하자.
R studio를 AWS에 설치하여 사용하는 것을 스터디에서 추천해주어서 해보았다.
일단 이글은 아래의 주소를 참조하여 만들었다.
https://aws.amazon.com/ko/blogs/big-data/running-r-on-aws/
amazon에서 올려준 글이므로 여기에 있는 여러 글들은 큰 도움이 된다.
먼저 로그인을 하면 아래와 같은 페이지가 나온다.
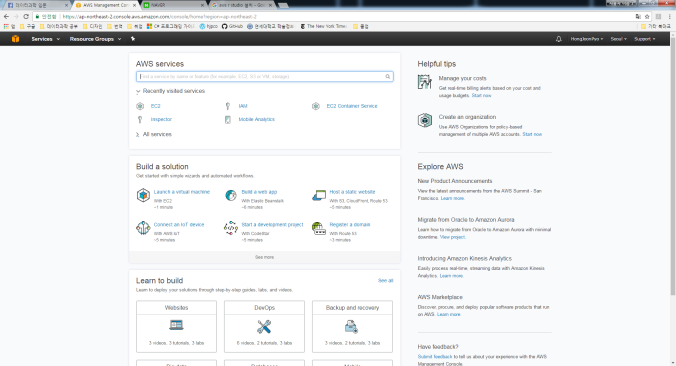
여기서 왼쪽 상단의 service를 누르고, 아래의 빨간 원처럼 ec2를 클릭한다.
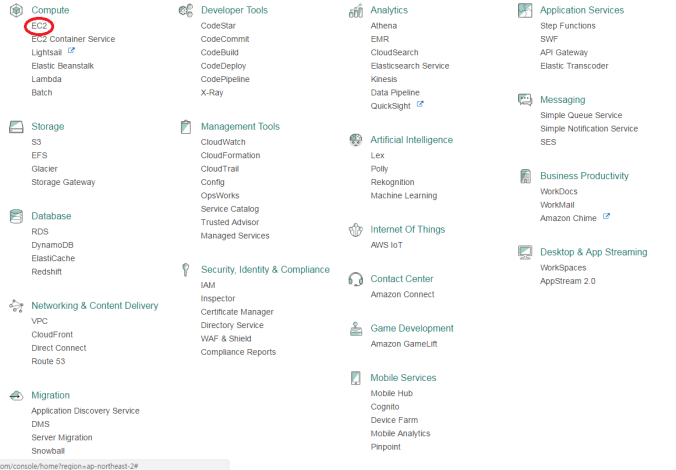
그러고 나면 아래의 페이지 처럼 나올 것이다.
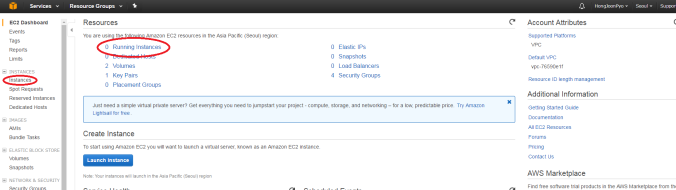
여기서 Runnig Instances나 왼쪽 목록에서 Instance를 누르면 아래와 같이 나오게 된다.
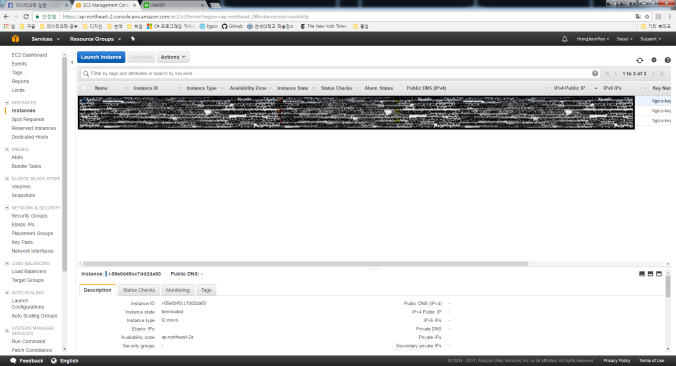
이제 위에 파란 버튼인 Launch instances 버튼을 눌러준다.
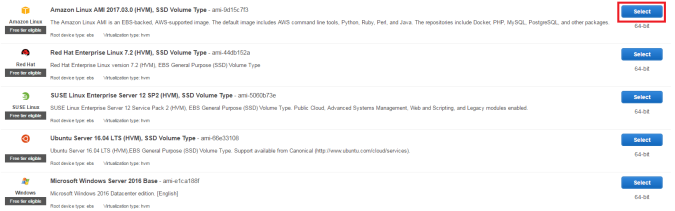
그러면 위처럼 어떤 AMI를 사용할지 나오게 된다.
기본인 Amazon Linux를 Select
다음을 누르면 Type을 선택하도록 되어 있다. 무료로 이용할 것 임으로 우리는 t2.micro를 선택하고 다음으로 넘어간다.
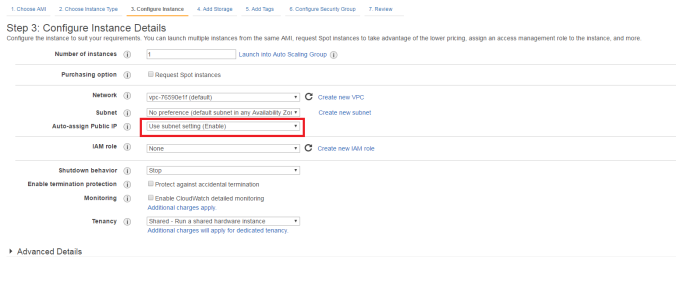
그러면 위와 같이 나온다. 이때 위 빨간 상자로 되어 있는 Auto-assign Public IP가 User subnet setting(Enable)이 아닌 Enable로 나오도록 바꾸어 주자.
이는 필자만 겪은 에러일 수도 있는데 region이 seoul일 경우 나중에 Instance가 public IP를 못 찾아오는 현상을 겪었기에 미리 예방하는 차원에서 바꾸어 준다.
그리고 계속 다음 다음 하다보면 Security Group을 설정하도록 되어있다.
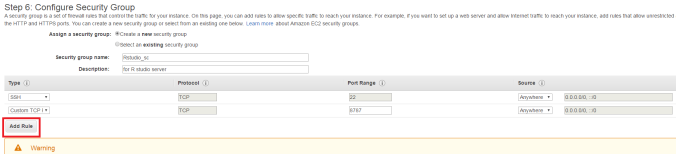
위에 사진처럼 Add Rule을 하여 8787 포트를 열어두자.
이렇게 해놓아야 Rstudio server에 접근이 가능하다.
SSH를 열어 놓은 것은 터미널로 접근하기 위해서 이다.
터미널로 접근하여 Rstudio server를 설치할 것임으로 필수이다!
(자신 외에 다른 사람의 접근을 허락하고 싶지 않은 경우 anywhere을 My IP로 바꿔준다.)
그렇게 Review and Launch를 누르고 다시 Launch를 누르게 되면 key pair를 선택하도록 나온다.
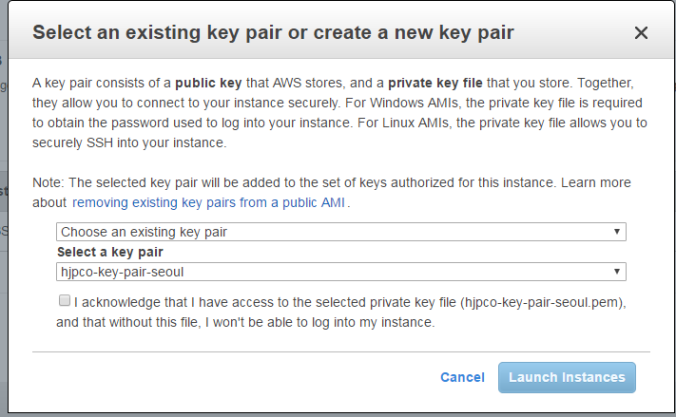
key pair는 설치하여도 좋고, 기존의 key pair를 선택하여 사용해도 상관 없다.
다만, 이름을 (username)-key-pair-(region) 식으로 하여 관리하는 것이 용이할 것이다.
여기에 사용한 key pair는 잃어버리지 않도록 주의해야 한다. 이때 key pair는 터미널로 접속하기 위해 필수적으로 필요하다.
체크를 하고 Lauch Instances를 하였다면 이상 없이 아래와 같이 나올 것이다.
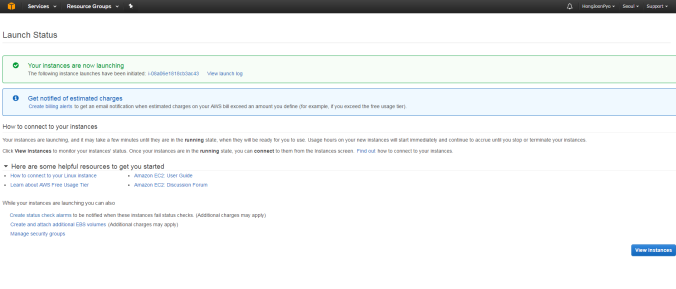
이제 터미널로 접근할 것이기 때문에 Putty의 설치가 필요하다.
https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.html
위 경로에서 자신의 OS bit에 맞는 것을 선택하여 설치하면 된다.
putty와 puttygen은 이 필요함으로 2개만 설치하여도 무관하다.
우선, puttygen을 실행한다.
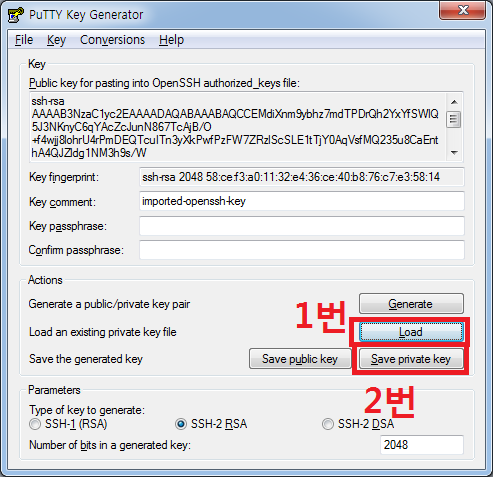
Load를 눌러 만든 instance에 사용된 key pair를 불러온다.
그뒤 Save private key를 눌러 .pem이라는 확장자로 새로운 key pair가 생기면 성공이다.
자세한 사항은 아래 사이트에 있다.
http://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/putty.html
이젠 putty로 instance에 연결을 시도하자
일단 이전에 생성한 instance가 running의 상태인지 확인하자.
stop이 되어 있다면 run시켜 주도록 하자.
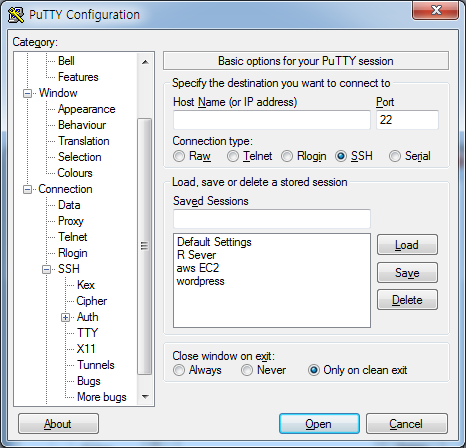
putty를 실행시키고 Host Name에는
ec2-user@(Public DNS)
ex) ec2-user@ec2-52-79-137-153.ap-northeast-2.compute.amazonaws.com
를 넣어준다.
이 주소는 다시 stop했다가 run할때마다 바뀜으로 모든 사용자가 다르게 가지고 있다. 그럼으로 자신의 instance가 가진 Public DNS로 작성해야한다.
이제 key pair를 연결하자
putty의 왼쪽 목록에서 [connection]-[SSH]-[Auth]로 들어가서 Browse…를 눌러 아까 puttygen으로 만든 .pem 파일을 연결시켜 준다.
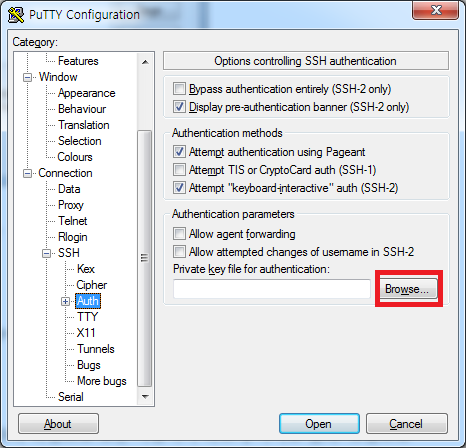
여기서 이전으로 돌아가려면 왼쪽 목록에서 session을 누르면 된다.
session으로 돌아오게 되면 바로 Open을 눌러도 되지만 다음 번에 접속할 수도 있으므로 미리 저장해두자.
이제 Open하여 연결하면 다음과 같은 메시지 창이 뜨는데 예(Y)를 누르고 들어가면 된다.
https://www.rstudio.com/products/rstudio/download-server/
위 주소에서 최신 Rstudio server 설치법을 보고 하였다.
우리는 Redhet/CentOS에 들어가 거기에 맞는 방법을 사용하면 된다.
먼저 R을 설치해야 함으로 다음과 같이 입력한다.
sudo yum install -y R
그리고 R studio Server를 다음과 같이 입력하여 설치한다.
wget https://download2.rstudio.org/rstudio-server-rhel-1.0.143-x86_64.rpm
sudo yum install –nogpgcheck rstudio-server-rhel-1.0.143-x86_64.rpm
설치하고 나면
rstudio-server start
하여 서버를 실행해 주자.
이제 (PublicDNS):8787입력하면 Rstdio 로그인 화면이 뜨게 된다.
ex) http://ec2-52-79-213-121.ap-northeast-2.compute.amazonaws.com:8787
로그인을 하게 되면 아래 처럼 R Studio를 이용할 수 있다.
로그인을 위해선 계정이 필요한데 터미널로 접속하여
useradd 계정명
echo ‘계정명:패스워드’ | chpasswd
라고 하면 된다.
비번을 바꾸는데 에러가 난다면,
sudo -s
를 입력하고 다시 바꿔보면 된다.
root계정이 아니면 passwd를 바꿀 수 없기 때문이다.
Datacamp R을 하고서 내용정리입니다!
chapter 1. 기본적인 명령어
chapter 2. Vectors
—-c(,) : ()안에 들어 있는 값들로 vector가 형성됨
——–ex) c(22,3) c(“42″,”1fj”) c(3.4,2.0,5.1)
—-names(vector) <- c(,) : vector의 각 값의 이름을 달아줌
——–ex) vector <- c(1,2,3)
————names(vector) <- c(“Mon”,”Thu”,”Wed”)
—-c(1,5) + c(3,6) : c(4,11) 각 안의 원소끼리 더해진다.
—-Selection
——–vector[c(1,4)] : 원하는 번째의 원소 불러오기
——–vector[c(1:4)] : 원하는 원소시작부터 끝까지 블러오기
——–vector[“Mon”] : 원하는 원소 이름으로 불러오기
—-비교
——–vector>0 : vector의 각 원소를 비교하여 TRUE FALSE로 나타낸 vector를 만든다.
————vector[vector>0] : 이런 식으로 vector에서 0이 넘는 값만 뽑은 vector를 만들 수도 있다.
chapter 3. Matrices
—-matrix(1:9, byrow = TRUE, nrow=3) : 매트릭스를 만드는 기본 명령어 nrow는 줄수를 의미 byrow는 줄을 기준으로 나눠짐을 의미
—-rowSums(matrix) : matrix의 각 row를 합한 vector 생성
—-colSums()
—-cbind(matrix1, matrix2, vector1,…) : You can add a column or multiple columns to a matrix with the cbind() function, which merges matrices and/or vectors together by column.
—-rbind()
—-Selection
——–matrix[,2:3] : matrix의 row는 모두 가져오고 col은 2:3만
—-matrix와 연산
——–matrix *2 : 각 값에 2가 곱해진 matrix 생성
——–matrix1/matrix2 : 각 위치에 맞는 값끼리 나누기
chapter 4. Factors
—-factor(c(“M”,”F”,”M”,”M”,”F”)) : Levels를 F,M으로 된 factor 생성
—-factor(vector1, order=TRUE, levels=vector2) : levels에 상위하위가 vector2의 순서에 따라 생김(맨처음이 가장 낮음)
—-levels(factor)<-vector : levels를 바꾸면서 기존에 있던 것도 따라서 값이 바뀜
—-summary
——–summary(vector) : vector의 Length, Class, Mode 출력
——–summary(factor) : levels에 따라 갯수 계산
—-ordered와 order : 둘이 같은 거 같다.
chapter 5. Data frames
—-head(matrix) : head만 출력
—-str(matrix) : 데이터를 빠르게 미리보기하는 명령어
—-data.frames(vc1,vc2,vc3,…) : vector들을 이어 dataframe을 만드는 명령어
—-Selection 기존과 같다.
——–추가로 head를 col값 대신 할 수 있다.
——–dataframe$headname : head명의 모든 값을 불러온다.
—-subset(dataframe, subset =if) : dataframe에서 조건에 맞는 값을 추출한다.
—-order(vector) : sort해준다.
——–dataframe[order(dataframe$headname),] : dataframe을 headname에 따라 정렬해서 출력한다.
chapter 6. Lists
—-Vectors (one dimensional array): can hold numeric, character or logical values. The elements in a vector all have the same data type.
—-Matrices (two dimensional array): can hold numeric, character or logical values. The elements in a matrix all have the same data type.
—-Data frames (two-dimensional objects): can hold numeric, character or logical values. Within a column all elements have the same data type, but different columns can be of different data type.
—-list(comp1,comp2,…) : list 생성
——–list는 vector, matrix, dataframe, 다른 list 모두를 포함가능하다
—-names(list)<-c(“1″,”2”,…) : list의 각 이름 변경
——–list <- list(name=n,age=a,…)처럼 간단히 사용도 가능
—-Selection
——–list[[2]] : list의 2번째 값 출력
——–list$name : list의 name 출력
——–list$name[[2]] : list의 name 중에 2번째 값 출력
——–list2<-c(list, year= value) : 연도가 value인 값만 list에서 뽑아내어 list2에 저장한다.
sum(값, na.rm=T)
:na.rm=TRUE로 함으로 써 NA값을 무시
matrix(값, row, col)
:값이 상수면 row와 col 크기의 배열을 만들고 주어진 상수로 채운다.
상수가 아니면 그 값들을 순서대로 채워간다.
plot(x,y)
contour(변수명)
: 지형의 높낮이처럼 2D로 표시
persp(변수명, expand=간격)
: 3D perspective plot으로 contour를 3D로 표현이라 생각하면 편함
image(변수명)
: heat map으로 색으로서 값의 변동을 표시
mean(변수명)
: 값들의 평균을 구해줌
abline(h=mean(변수명))
: barplot으로 표현했을 때 높이가 평균인 선을 하나 표시
median(변수명)
: 값들의 중간값을 구해줌
sd(변수명)
: 값들의 standard deviation(표준편차)를 구해줌
factor(변수명)
: 값들의 중복이 제외하여 Levels로 표현
as.integer(factor(변수명))
: 값들의 중복을 제거하고 주어진 level의 위치를 표시
ex) > chests<-c(‘gold’,’silver’,’gems’,’gold’,’gems’) > as.integer(factor(chests))
[1] 2 3 1 2 1
levels(factor(변수명))
: facotr로 만들어진 Levels의 값들을 표시
ex) > chests<-c(‘gold’,’silver’,’gems’,’gold’,’gems’) > levels(factor(chests))
[1] “gems” “gold” “silver”
plot(x,y,pch=as.integer(factor(변수명)))
: (x,y)의 값에 상관없이 입력된 변수명에 따라 같은 것들은 값은 모양으로 표시된다.
data.frame(값, 값2, 값3)
: 값, 값2, 값3으로 이루어진 matrix가 만들어진다.
ex)
weights prices types
1 300 9000 gold
2 200 5000 silver
3 100 12000 gems
4 250 7500 gold
5 150 18000 gems
변수명[[x]]
: x 번째 col이 전체 출력된다.
ex) > tresure[[2]]
[1] 9000 5000 12000 7500 18000
변수명[[변수명2]] == 변수명$변수명2
: 변수명2 의 값들이 전체 출력된다.
ex) treasure[[“weights”]] == treasure$weights
read
.csv(“*.csv”)
: *.csv파일을 읽어온다.
.table(“*.txt”, sep=”\t”)
: *.txt를 불러오는데 값 구분을 탭으로 한다.
.tabel(“*.txt”, sep=”\t”, header=”TRUE”)
: 위와 같으나 data의 header를 “V1”,”V2″와 같이 자동 지정이 아니라 첫번째 값을 header로 한다.
merge(x=변수명, y=변수명2)
: x로 불러온 값을 기준으로 y로 불러온 값을 추가한다. 이때 첫번째 col 값을 기준 정렬한다.
ex)
> targets infantry merge(x = targets, y = infantry)
Port Population Worth Infantry
1 Cartagena 35000 10000 500
2 Havana 140000 50000 2000
3 Panama City 105000 35000 1500
4 Porto Bello 49000 15000 700
plot(x,y)
abline(lm(x~y))
: x와 y로 이루어진 그래프에 값들을 이용한 유사 직선을 그려준다.
install.package(“ggplot2”)
: “ggplot2″의 패키지를 다운받고 이용가능도록 해준다.
qplot(x, y, color = z)
: x, y로 이루어진 plot을 그리고 색은 z에 따라 설정한다.
범례도 출력되며 칼라이다.
갑작스레 정리한 이유는 R이 머리 속에서 정리가 잘 되지 않아서이다.
