이제 우리는 수치적으로 물품간의 상관관계를 알 필요가 있다.
그러므로써 구매할 물품을 추천해주는 시스템을 구축하는 것이 가능해진다.
이제부터 우리가 이를 위해 사용할 알고리즘이 장바구니(Apriori) 알고리즘이다
(정도현 선배님과 김은정 선배님께 도움을 받았습니다)
이는 장바구니 알고리즘을 google에 검색하였을 때 가장 먼저 접하게 된 알고리즘이다.
그래서 장바구니 알고리즘에 가장 자주 사용되거나 기초가 되는 알고리즘이라고 생각했다.
그렇다면 이 알고리즘은 우리가 하려는 추천시스템에 사용 가능한지 알기 위해 내용을 알아보자.
결과
우선 결과부터 알아보고 넘어가자.
apriori라는 방식으로는 우리가 가진 데이터가 너무 크기 때문에 결과값을 구하는데 너무 오래걸린다.
오래걸리는 것보다도 데이터 낭비라든지 별로 좋아보이는 형태가 아니다.
그래서 더 나은 것을 찾아 더 구글링해보기로 했다!
하지만 방법이 없다면 다시 여기로 돌아와야지…
연관관계 기본 개념
우리는 먼저 연관관계를 규정하는 몇개의 정의를 알아야한다.
- Support
- supp(X) = P(X)
전체에서 X의 확률
- supp(X) = P(X)
- Confidence
- conf(X -> Y) = P(Y | X) = supp(X ∪ Y) / supp(X)
X일떄 Y의 확률, 즉 X 구매시 Y를 구매할 확률이 된다.
- conf(X -> Y) = P(Y | X) = supp(X ∪ Y) / supp(X)
- Lift
- lift(X -> Y) = supp(X ∪ Y) / [ supp(Y) * supp(X) ]
향상도라고 부르며, X를 구매할 때 Y도 구매할 확률로 보자.
- lift(X -> Y) = supp(X ∪ Y) / [ supp(Y) * supp(X) ]
- Conviction
- conv(X -> Y) = [ 1 – supp(Y) ] / [ 1 – conf(X -> Y) ]
X에서 Y를 구매할 때 연관성을 구해준다.
- conv(X -> Y) = [ 1 – supp(Y) ] / [ 1 – conf(X -> Y) ]
Apriori Algorithm Example
예시를 통해 Apriori 알고리즘이 무엇인지 알아보도록 하자.
구매목록 |
| {1, 2, 3, 4} |
| {1, 2, 4} |
| {1, 2} |
| {2, 3, 4} |
| {2, 3} |
| {3, 4} |
| {2, 4} |
위와 같이 구매 목록이 있다고 하자. 총 7개의 목록이 있다.
support는 비율로 나타낼 수도 있지만 총 수가 적으므로 count로 표시하자.
C1, C2, C3는 각각 물품을 1개, 2개, 3개가 있는 그룹이다.
앞으로 Cn은 n개의 물품이 있는 목록의 supp이 있는 그룹이라고 하자.
그럼 1~4까지의 물품이 있고 각각의 supp은 아래와 같다. 이를 C1이라 부르자.
물품명 |
Support |
| {1} | 3 |
| {2} | 6 |
| {3} | 4 |
| {4} | 5 |
보면 {1}이 3으로 가장 Support가 낮다.
이를 min_sup으로 하자. 이보다 낮으면 제외하기로 한다.
이제 C2를 보자.
물품명 |
Support |
| {1, 2} | 3 |
| {1, 3} | 1 |
| {1, 4} | 2 |
| {2, 3} | 3 |
| {2, 4} | 4 |
| {3, 4} | 3 |
위를 보면 {1, 3}과 {1, 4}가 min_sup보다 낮다.
이제 {1, 3}과 {1, 4}가 들어가지 않도록 C3를 만들자.
물품명 |
Support |
| {2, 3, 4} | 2 |
C3는 위와 같이 {2, 3, 4}만이 나온다.
그럼 지금까지 구한 것을 토대로 보면 {2, 3, 4}가 연관성이 큰 집단이라고 볼 수 있다.
이러한 방식으로 Apriori 알고리즘은 집단의 연관성이 있는 물품들을 알려준다.
R로 알아보기
이제 Groceries.csv 파일을 토대로 R로 프로그래밍 해보자.
파일 : Groceries.csv
library("arules")
library("arulesViz")
#Load data set
data("Groceries")
summary(Groceries)
#Look at data
inspect(Groceries[1])
LIST(Groceries)[1]
#Calculate rules using apriori algorithm and specifying support and confidence thresholds:
rules = apriori(Groceries, parameter=list(support=0.01, confidence=0.05))
#Inspect the top 5 rules in terms of lift
inspect(head(sort(rules, by="lift"), 5))
#Plot a frequency plot
itemFrequencyPlot(Groceries, topN = 25)
#Scatter plot of rules:
library("RColorBrewer")
plot(rules, control=list(col=brewer.pal(11,"Spectral")),main="")
#Rules with high lift typically have low support.
#The most interesting rules reside on the support/confidence border which can be clearly seen in this plot.
#Plot graph-based visualisation:
subrules2 <- head(sort(rules, by="lift"), 10)
plot(subrules2, method="graph", control=list(type="items", main=""))
package는 기본적으로 ‘arules’, ‘arulesViz’ 두개가 필요하다.
나중에 plot으로 표현하기 위해 ‘RColorBrewer’도 추가로 필요하다.
세 패키지를 library 함수로 부착시킨다.
만약 설치되어 있지 않다면 install.packages(“arules”), install.packages(“arulesViz”), install.packages(“RColorBrewer”)로 설치한다.
그리고 데이터를 받아온다.
data(“Groceries”)
이제 받아온 데이터로 간단히 통계를 내보자.
summary(Groceries)
![[summary]data.png](https://hjpco.wordpress.com/wp-content/uploads/2017/06/summarydata.png?w=676)
전체 9835개의 행과 169개의 열로 이루어져있다.
가장 많이 나온 항목(most frequent items)은 whole milk로 2513개 이다.
데이터 길이가 가장 큰 것(sizes)은 2159이며, 최소값(Min.) 1, 중간값(Median) 3, 평균(Mean) 4.409, 최대값(Max) 32이 이다.
간단히 데이터를 확인하고 넘어가자.
inpect(Groceries[1])
LIST(Groceries)[1]
결과는 확인해보길 바란다.
rules = apriori(Groceries, parameter=list(support=0.01, confidence=0.05))
이제 드디어 apriori 함수를 이용하여 결과값을 확인해보자.
![[apriori]data](https://hjpco.wordpress.com/wp-content/uploads/2017/06/aprioridata.png?w=676)
min_sup은 0.01, min_conf는 0.05로 설정하였다.
값을 다르게 설정하면 결과값도 당연히 다르게 나온다.
결과는 위와 같다. 이렇게 보면 뭐가뭔지 감이 잘 안잡히므로 다른 그래프로 확인해보자.
일단, 자주 팔렸던 상품 25개 그래프이다.
itemFrequencyPlot(Groceries, topN = 25)
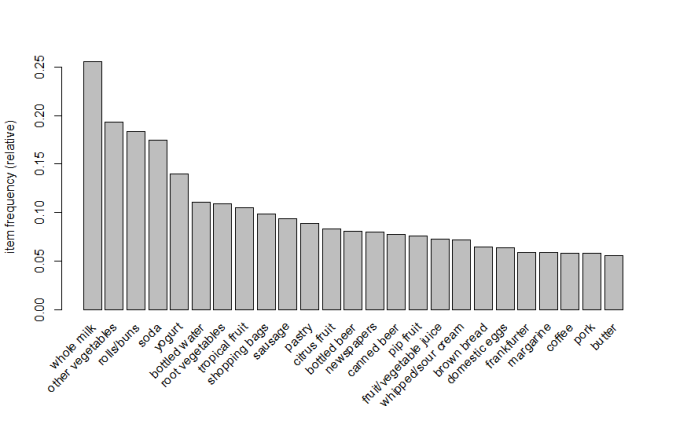
아까 summary로 확인한 것과 다름이 없음을 알 수 있다.
다만, 더 많은 상품을 볼 수도 있고, 크기 비교를 눈으로 확인할 수 있다.
얻은 Apriori결과 값으로 support와 confidence로 그래프를 얻었다.
plot(rules, control=list(col=brewer.pal(11,”Spectral”)),main=””)
![[support]confidence](https://hjpco.wordpress.com/wp-content/uploads/2017/06/supportconfidence.png?w=676)
위의 그래프로 보아 support와 confidence의 관계가 반비례함을 알 수 있다.
좀더 알아보기 쉽도록 표현해보자.
lift값을 기준으로 상위 10개 물품을 표현해보자.
plot(subrules2, method=”graph”, control=list(type=”items”, main=””))
![[support]lift](https://hjpco.wordpress.com/wp-content/uploads/2017/06/supportlift.png?w=676)
위를 보면 baking poweder와 flour를 사는 경우에는 sugar를 살 가능성이 가장 큼을 알 수 있다.
그 이유는 색이 진할 수록 lift 값이 높고 크기가 클 수록 support 값이 크기 때문이다.
support 값으로 큰 것과 물건 간의 관계를 보는 것 보다 관계에서는 lift 값을 보는 것이 더 타당함으로 위와 같이 말 할 수 있다.
한계
apriori 알고리즘의 한계는 바로 속도이다.
위를 보면 알겠지만 일부분만 한 이유도 속도가 굉장히 느리기 때문이다.
그런 apriori 알고리즘을 보안하기 위해 partitioning, DHP, ECLAT 3가지 방법이 있는데
이를 알아보자.
Partitioning
어느 상품이 자주 나오지 않으면 그 상품이 포함된 세트도 자주 나오지 않기 때문에, 어떤 세트가 자주나오려면 그 세트의 상품들을 나누었을 때 그 중 하나는 자주나오는 세트이어야 한다.
이 이론이 바탕이 된다.
사실 적어놓고 이해하기 힘들거라 생각하기에 예를 들어 보겠다.
우리가 사과와 배를 사는 사람이 많은지 보려고 한다.
그럼 적어도 사과나 배가 많이 팔려야 그 두개를 같이 사는 사람이 많다.
위 논리가 바탕이 되어서 역으로 추정해보는 것이다.
그러면 사과와 배가 세트로 많이 팔린다면 적어도 사과나 배 둘 중 하나는 많이 팔려야 한다는 것이다.
여기서 사과와 배로 나누는 것을 partitioning이라 한다.
그러므로 가장 큰 세트로 부터 시작해서 partitoning하면서 시작하므로, 쓸데없이 작은 수치의 세트를 거치지 않고 apriori algorithm 적용이 가능하다.
아래는 참고 그림이다.
![[apriori]partitioning.jpeg](https://hjpco.wordpress.com/wp-content/uploads/2017/06/aprioripartitioning.jpeg?w=676)
DHP(Direct Hasing and Pruning)
DHP는 상품이 정해진 수치이상으로 구매된다면,
그 상품이 포함된 세트의 구매량도 수치이상이 될 수 있다는 이론이다.
이 이론으로도 시간은 많이 줄일 수 있지만, 원하는 만큼 줄지 않으므로 길게 적진 않겠다.
아래 그림을 참고하여 이해해주길 바란다.
![[apriori]DHP.jpg](https://hjpco.wordpress.com/wp-content/uploads/2017/06/aprioridhp.jpg?w=676)
ECLAT(Equivalence Class Transformation)
ECLAT는 apriori처럼 하나의 큰 틀이 되는 Algorithm으로 볼 수 있지만 여기선 간략히 보도록 하겠다.
기본적으로 상품을 기준으로 접근하는 방법이다.
표를 일단 2가지로 나누어야한다.
주문에 따라 구매물품이 있는 표와 물품에 따라 주문번호가 있는 표가 필요하다.
t(X) = X라는 상품이 주문된 번호들을 뜻한다.
상품 X와 Y가 있을 때 t(X)와 t(Y) 둘이 같다면 언제나 같이 구매된다는 뜻이고,
t(X)가 t(Y)에 속한다면 X가 구매될 땐 항상 Y도 구매된다는 의미이다.
여기에 차집합을 이용하는 것이다.
t(Y) – t(X)를 하면 X가 일어날 때 Y도 반드시 일어남으로 그 외의 경우를 알 수 있다.
그 외의 경우에는 다른 방법을 적용하여 해결하는 것이다.
아래 그림을 참고하길 바란다.
![[apriori]ECLAT.jpg](https://hjpco.wordpress.com/wp-content/uploads/2017/06/apriorieclat.jpg?w=676)
다음에는…
이로써, apriori를 전반적으로 살펴보았다.
이제 apriori는 우리에게 맞지 않다는 것을 알 수 있었다.
그러므로 apriori를 검색하다보면 frequent pattern Algorithm에 대해서 알게 되었다.
이 중 apriori가 아닌 FP-Growth 방법이 있다. 다음에는 이 방법에 대해 알아보도록 하자.
Reference
http://rfriend.tistory.com/192
Lab8-Apriori.pdf에 액세스하려면 클릭하세요.
https://algobeans.com/2016/04/01/association-rules-and-the-apriori-algorithm/
https://select-statistics.co.uk/blog/market-basket-analysis-understanding-customer-behaviour/
https://www.singularities.com/blog/2015/08/apriori-vs-fpgrowth-for-frequent-item-set-mining

감사합니다! 잘 보고 갑니다~^^
좋아요좋아요